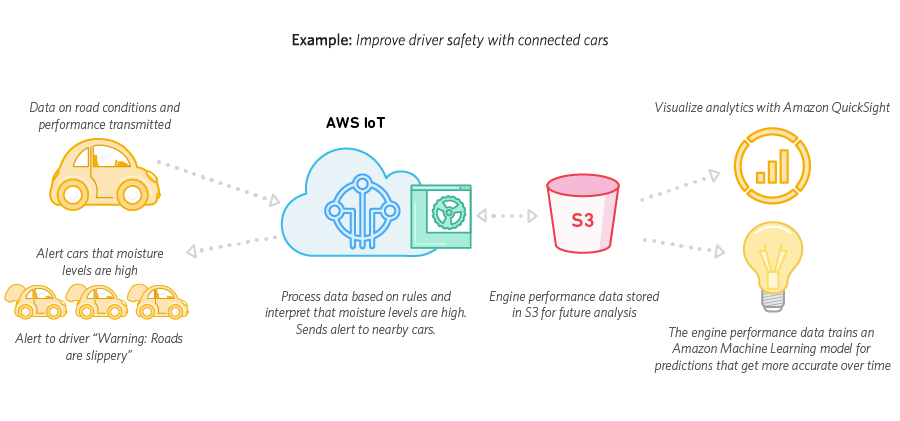
Hay muchos factores para elegir si procesar los datos en el dispositivo o en la nube.
Beneficios del procesamiento en la nube
Si el algoritmo utiliza coma flotante o se ejecuta en una GPU, es posible que no se pueda ejecutar en el procesador incorporado en el sensor.
Incluso si no es así, si el algoritmo se desarrolló en un lenguaje de alto nivel, podría ser demasiado costoso (en tiempo de desarrollador) portarlo para que se ejecute en el sensor.
La descarga del cálculo del sensor puede aumentar la duración de la batería (dependiendo de cómo esto afecte el uso de la red / radio).
Ejecutar el algoritmo en la nube le permite combinar los datos de muchos sensores y tomar una decisión a nivel de sistema. En este ejemplo, eso podría significar filtrar a través de los sensores de diferentes automóviles, de modo que lavar un automóvil no cause una advertencia de lluvia en todos los automóviles.
El procesamiento en la nube permite distribuir la información a muchos lugares sin tener que tener una red de malla, que es una arquitectura complicada.
Puede registrar más datos, lo que permite mejores análisis, auditorías y desarrollo de mejores algoritmos.
Beneficios del procesamiento a bordo
Si los datos sin procesar del sensor son de gran ancho de banda, podría usar menos batería para resumir los datos y enviar el resumen (dependiendo de qué procesamiento se necesite para resumirlo ). Esto podría significar que, en lugar de enviar una lectura de humedad de 8 bits 100 veces por segundo, la filtra y envía una bandera húmeda / seca de 1 bit cada 10 segundos.
Puede ir más allá y solo despertar la red cuando el sensor tenga algo interesante que informar (por ejemplo, los cambios de estado húmedo / seco)
Reducir el ancho de banda de la red en el extremo del sensor también lo reduce en el extremo del servidor, por lo que puede escalar el servicio a más usuarios (más sensores) de manera muy económica.
Puede ser posible ejecutar el servicio con la misma funcionalidad o reducida incluso cuando la red no está disponible. En este ejemplo, su automóvil podría advertirle sobre carreteras resbaladizas que se ve a sí mismo, pero no le avisará con anticipación de otros automóviles.
En general
Por lo general, alguna combinación de los dos es óptima. Puede realizar todo el procesamiento que pueda permitirse en el dispositivo, para reducir la necesidad de la red tanto como sea posible, y luego ejecutar algoritmos más sofisticados en la nube que puedan combinar más entradas o usar más potencia de cálculo.
Puede comenzar a ejecutar todo su procesamiento en la nube (porque fue prototipado en Matlab o Python) y transferir partes gradualmente a Rust para habilitar la funcionalidad fuera de línea, cuando tenga tiempo de desarrollador para dedicarlo.
Es posible que procese los datos en gran medida en el dispositivo en uso normal, pero también muestree y registre los datos sin procesar a veces, para poder cargarlos en la nube más tarde (cuando la red esté más disponible) para sus análisis.