Recientemente hice una tarea donde tuve que aprender un modelo para la clasificación de 10 dígitos del MNIST. El HW tenía un código de andamiaje y se suponía que debía trabajar en el contexto de este código.
Mi tarea funciona / pasa las pruebas, pero ahora estoy tratando de hacerlo todo desde cero (mi propio nn framework, sin código de andamio hw) y estoy atascado aplicando el grandient de softmax en el paso de backprop, e incluso pienso en lo que hw el código de andamio podría no ser correcto.
El hw me hace usar lo que ellos llaman 'una pérdida de softmax' como el último nodo en el nn. Lo que significa que, por alguna razón, decidieron unir una activación de softmax con la pérdida de entropía cruzada, todo en uno, en lugar de tratar softmax como una función de activación y la entropía cruzada como una función de pérdida separada.
La función hw loss se ve así (editada mínimamente por mí):
class SoftmaxLoss:
"""
A batched softmax loss, used for classification problems.
input[0] (the prediction) = np.array of dims batch_size x 10
input[1] (the truth) = np.array of dims batch_size x 10
"""
@staticmethod
def softmax(input):
exp = np.exp(input - np.max(input, axis=1, keepdims=True))
return exp / np.sum(exp, axis=1, keepdims=True)
@staticmethod
def forward(inputs):
softmax = SoftmaxLoss.softmax(inputs[0])
labels = inputs[1]
return np.mean(-np.sum(labels * np.log(softmax), axis=1))
@staticmethod
def backward(inputs, gradient):
softmax = SoftmaxLoss.softmax(inputs[0])
return [
gradient * (softmax - inputs[1]) / inputs[0].shape[0],
gradient * (-np.log(softmax)) / inputs[0].shape[0]
]
Como puede ver, en adelante hace softmax (x) y luego cruza la pérdida de entropía.
Pero en backprop, parece que solo hace la derivada de entropía cruzada y no de softmax. Softmax se deja como tal.
¿No debería tomar también la derivada de softmax con respecto a la entrada a softmax?
Suponiendo que debería tomar la derivada de softmax, no estoy seguro de cómo este hw realmente pasa las pruebas ...
Ahora, en mi propia implementación desde cero, hice softmax y nodos separados de entropía cruzada, así (p y t significan predicción y verdad):
class SoftMax(NetNode):
def __init__(self, x):
ex = np.exp(x.data - np.max(x.data, axis=1, keepdims=True))
super().__init__(ex / np.sum(ex, axis=1, keepdims=True), x)
def _back(self, x):
g = self.data * (np.eye(self.data.shape[0]) - self.data)
x.g += self.g * g
super()._back()
class LCE(NetNode):
def __init__(self, p, t):
super().__init__(
np.mean(-np.sum(t.data * np.log(p.data), axis=1)),
p, t
)
def _back(self, p, t):
p.g += self.g * (p.data - t.data) / t.data.shape[0]
t.g += self.g * -np.log(p.data) / t.data.shape[0]
super()._back()
Como puede ver, mi pérdida de entropía cruzada (LCE) tiene la misma derivada que la de hw, porque esa es la derivada de la pérdida en sí, sin entrar todavía en el softmax.
Pero entonces, todavía tendría que hacer la derivada de softmax para encadenarla con la derivada de la pérdida. Aquí es donde me quedo atascado.
Para softmax definido como:
La derivada generalmente se define como:
Pero necesito una derivada que dé como resultado un tensor del mismo tamaño que la entrada a softmax, en este caso, batch_size x 10. Por lo tanto, no estoy seguro de cómo se debe aplicar lo anterior a solo 10 componentes, ya que implica que yo diferenciaría para todas las entradas con respecto a todas las salidas (todas las combinaciones) o en forma de matriz.
fuente
Respuestas:
Después de seguir trabajando en esto, descubrí que:
La implementación de tareas combina softmax con pérdida de entropía cruzada como una opción, mientras que mi elección de mantener softmax separado como una función de activación también es válida.
La implementación de la tarea no tiene la derivada de softmax para el pase de backprop.
El gradiente de softmax con respecto a sus entradas es realmente el parcial de cada salida con respecto a cada entrada:
Entonces, para la forma vectorial (gradiente):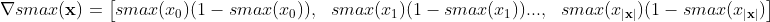
Lo que en mi código numpy vectorizado es simplemente:
Donde
self.dataestá el softmax de la entrada, previamente calculado a partir del pase directo.fuente