En las escuelas de todo el mundo, los niños escriben un número en su calculadora LCD, lo ponen boca abajo y se echan a reír después de crear la palabra 'Bobos'. Por supuesto, esta es la palabra más popular, pero hay muchas otras palabras que se pueden producir.
Sin embargo, todas las palabras deben tener menos de 10 letras (sin embargo, el diccionario contiene palabras más largas que esta, por lo que debe realizar un filtro en su programa). En este diccionario, hay algunas palabras en mayúscula, por lo tanto, convierta todas las palabras en minúsculas.
Usando un diccionario de idioma inglés, cree una lista de números que se pueden escribir en una calculadora LCD y crea una palabra. Al igual que con todas las preguntas de código de golf, gana el programa más corto para completar esta tarea.
Para mis pruebas, utilicé la lista de palabras UNIX, reunida escribiendo:
ln -s /usr/dict/words w.txt
O, alternativamente, consíguelo aquí .
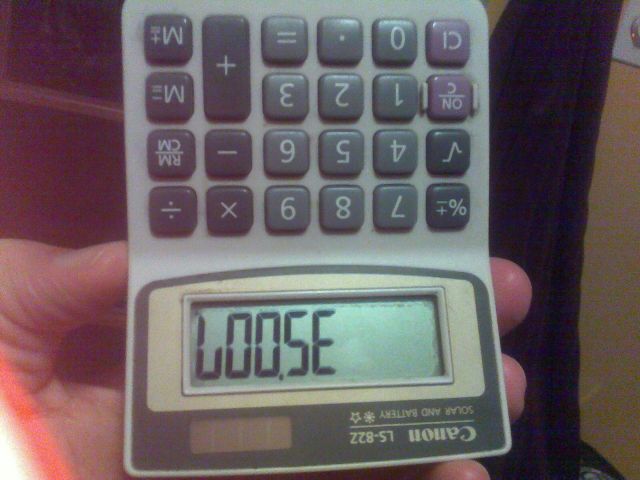
Por ejemplo, la imagen de arriba se creó escribiendo el número 35007en la calculadora y dándole la vuelta.
Las letras y sus respectivos números:
- b :
8 - g :
6 - l :
7 - yo :
1 - o :
0 - s :
5 - z :
2 - h :
4 - e :
3
Tenga en cuenta que si el número comienza con un cero, se requiere un punto decimal después de ese cero. El número no debe comenzar con un punto decimal.
Creo que este es el código de MartinBüttner, solo quería acreditarte por ello :)
/* Configuration */
var QUESTION_ID = 51871; // Obtain this from the url
// It will be like http://XYZ.stackexchange.com/questions/QUESTION_ID/... on any question page
var ANSWER_FILTER = "!t)IWYnsLAZle2tQ3KqrVveCRJfxcRLe";
/* App */
var answers = [], page = 1;
function answersUrl(index) {
return "http://api.stackexchange.com/2.2/questions/" + QUESTION_ID + "/answers?page=" + index + "&pagesize=100&order=desc&sort=creation&site=codegolf&filter=" + ANSWER_FILTER;
}
function getAnswers() {
jQuery.ajax({
url: answersUrl(page++),
method: "get",
dataType: "jsonp",
crossDomain: true,
success: function (data) {
answers.push.apply(answers, data.items);
if (data.has_more) getAnswers();
else process();
}
});
}
getAnswers();
var SIZE_REG = /\d+(?=[^\d&]*(?:<(?:s>[^&]*<\/s>|[^&]+>)[^\d&]*)*$)/;
var NUMBER_REG = /\d+/;
var LANGUAGE_REG = /^#*\s*([^,]+)/;
function shouldHaveHeading(a) {
var pass = false;
var lines = a.body_markdown.split("\n");
try {
pass |= /^#/.test(a.body_markdown);
pass |= ["-", "="]
.indexOf(lines[1][0]) > -1;
pass &= LANGUAGE_REG.test(a.body_markdown);
} catch (ex) {}
return pass;
}
function shouldHaveScore(a) {
var pass = false;
try {
pass |= SIZE_REG.test(a.body_markdown.split("\n")[0]);
} catch (ex) {}
return pass;
}
function getAuthorName(a) {
return a.owner.display_name;
}
function process() {
answers = answers.filter(shouldHaveScore)
.filter(shouldHaveHeading);
answers.sort(function (a, b) {
var aB = +(a.body_markdown.split("\n")[0].match(SIZE_REG) || [Infinity])[0],
bB = +(b.body_markdown.split("\n")[0].match(SIZE_REG) || [Infinity])[0];
return aB - bB
});
var languages = {};
var place = 1;
var lastSize = null;
var lastPlace = 1;
answers.forEach(function (a) {
var headline = a.body_markdown.split("\n")[0];
//console.log(a);
var answer = jQuery("#answer-template").html();
var num = headline.match(NUMBER_REG)[0];
var size = (headline.match(SIZE_REG)||[0])[0];
var language = headline.match(LANGUAGE_REG)[1];
var user = getAuthorName(a);
if (size != lastSize)
lastPlace = place;
lastSize = size;
++place;
answer = answer.replace("{{PLACE}}", lastPlace + ".")
.replace("{{NAME}}", user)
.replace("{{LANGUAGE}}", language)
.replace("{{SIZE}}", size)
.replace("{{LINK}}", a.share_link);
answer = jQuery(answer)
jQuery("#answers").append(answer);
languages[language] = languages[language] || {lang: language, user: user, size: size, link: a.share_link};
});
var langs = [];
for (var lang in languages)
if (languages.hasOwnProperty(lang))
langs.push(languages[lang]);
langs.sort(function (a, b) {
if (a.lang > b.lang) return 1;
if (a.lang < b.lang) return -1;
return 0;
});
for (var i = 0; i < langs.length; ++i)
{
var language = jQuery("#language-template").html();
var lang = langs[i];
language = language.replace("{{LANGUAGE}}", lang.lang)
.replace("{{NAME}}", lang.user)
.replace("{{SIZE}}", lang.size)
.replace("{{LINK}}", lang.link);
language = jQuery(language);
jQuery("#languages").append(language);
}
}body { text-align: left !important}
#answer-list {
padding: 10px;
width: 50%;
float: left;
}
#language-list {
padding: 10px;
width: 50%px;
float: left;
}
table thead {
font-weight: bold;
}
table td {
padding: 5px;
}<script src="https://ajax.googleapis.com/ajax/libs/jquery/2.1.1/jquery.min.js"></script>
<link rel="stylesheet" type="text/css" href="//cdn.sstatic.net/codegolf/all.css?v=83c949450c8b">
<div id="answer-list">
<h2>Leaderboard</h2>
<table class="answer-list">
<thead>
<tr><td></td><td>Author</td><td>Language</td><td>Size</td></tr>
</thead>
<tbody id="answers">
</tbody>
</table>
</div>
<div id="language-list">
<h2>Winners by Language</h2>
<table class="language-list">
<thead>
<tr><td>Language</td><td>User</td><td>Score</td></tr>
</thead>
<tbody id="languages">
</tbody>
</table>
</div>
<table style="display: none">
<tbody id="answer-template">
<tr><td>{{PLACE}}</td><td>{{NAME}}</td><td>{{LANGUAGE}}</td><td>{{SIZE}}</td><td><a href="{{LINK}}">Link</a></td></tr>
</tbody>
</table>
<table style="display: none">
<tbody id="language-template">
<tr><td>{{LANGUAGE}}</td><td>{{NAME}}</td><td>{{SIZE}}</td><td><a href="{{LINK}}">Link</a></td></tr>
</tbody>
</table>
0.7734para hola o sería.7734aceptable?0.7734es obligatoriooligorequiere un cero detrás después del punto decimal:0.6170Respuestas:
CJam,
4442 bytesPruébelo en línea en el intérprete de CJam .
Para ejecutar el programa desde la línea de comandos, descargue el intérprete de Java y ejecute:
Cómo funciona
fuente
Bash + coreutils, 54
Nuevamente, gracias a @TobySpeight por la ayuda en el golf.
La lista de palabras de entrada se toma de STDIN:
fuente
Pitón 2,
271216211205 BytesEsta es la única idea que he tenido hasta ahora ... ¡Actualizaré esto una vez que piense en otra cosa! Supuse que necesitábamos leer de un archivo, pero si no, hágamelo saber para que pueda actualizar :)
Muchas gracias a Dennis por salvarme 55 bytes :)
También gracias a Sp3000 por guardar 6 bytes :)
fuente
"oizehsglb".index(b)más corto?d[b] == "oizehsglb".index(b). Posiblemente carezca de un elenco para cadena / personaje..findes más corto que.index, 2) Dependiendo de la versión que tenga, al menos en 2.7.10opensin un argumento de modo predeterminador, 3) ¿Nofor x in open(...)funciona? (puede que sea necesario eliminar una nueva línea final) Si no es así, entonces.split('\n')es más corta que.splitlines()g+=[['0.'+c[1:],c][c[0]!='0']]*c.isdigit(), y puede ahorrar algunos más invirtiendo yfluego haciendo enfor c in flugar de tenerc=x[::-1]. Además, solo lo usafuna vez, por lo que no necesita guardarlo como una variableJavaScript (ES7), 73 bytes
Esto se puede hacer en ES7 a solo 73 bytes:
Sin golf:
Uso:
Función:
Ejecuté esto en la lista de palabras de UNIX y puse los resultados en una papelera:
Resultados
El código utilizado para obtener los resultados en Firefox :
fuente
t('Impossible')?Python 2, 121 bytes
Asume que el archivo del diccionario
w.txttermina con una nueva línea final y no tiene líneas vacías.fuente
GNU sed, 82
(incluido 1 para
-r)Gracias a @TobySpeight por la ayuda en el golf.
La lista de palabras de entrada se toma de STDIN:
fuente
TI-BASIC,
7588 byteseditar 2: no importa, esto todavía es técnicamente inválido, ya que solo acepta una palabra a la vez (no un diccionario). Trataré de arreglarlo para permitir más de una palabra como entrada ...
editar: oops; Originalmente hice que mostrara un .0 al final si el último número era 0, no al revés. Se corrigió, aunque esta es una solución alternativa (muestra "0" junto al número si comienza con 0, de lo contrario, muestra dos espacios en el mismo lugar). En el lado positivo, maneja correctamente palabras como "Otto" (muestra ambos ceros) ya que en realidad no muestra un número decimal.
No puedo pensar en un mejor idioma para hacerlo. Definitivamente se puede jugar más al golf, pero ahora estoy demasiado cansado. La tilde es el símbolo de negación [el( - ) botón].
Input is taken from the calculator's answer variable, meaning whatever was last evaluated (like
_in the interactive python shell) so you have to type a string on the homescreen (quote mark is on ALPHA+), press ENTER, then run the program. Alternatively, you can use a colon to separate commands, so if you name the program, say, "CALCTEXT" and you want to run it on the string "HELLO", you can type"HELLO":prgmCALCTEXTinstead of doing them separately.fuente
Python 2,
147158156 bytesI was missing this '0.' requirement. Hope now it works allright.
edit: Removed ".readlines()" and it still works ;p
edit2: Removed some spaces and move print to the 3rd line
edit3: Saved 2 bytes thanks to Sp3000 (removed space after print and changed 'index' to 'find')
fuente
Python 2,
184174 bytesfuente
Ruby 2,
8886 bytesByte count includes 2 for the
lnoptions on the command line:fuente
==""can be replaced with<?A. And no need forgsub()assub()is enough.C,
182172169/181172 bytesExpanded
using the linked words.txt, with lower case conversion:
fuente
*s|32work as lowercase conversion in this context?Haskell, 175 bytes without imports (229 bytes with imports)
Relevant code (say in File Calc.hs):
fuente
Java,
208200176 bytesExpanded
It always adds the decimal, and when invalid returns " . ". But otherwise works like it should. :P
Thanks @LegionMammal978!
fuente
;String l=to,l=and=o+to+=.