Soy uno de los autores de Gimli. Ya tenemos una versión de 2 tweets (280 caracteres) en C, pero me gustaría ver qué tan pequeña puede ser.
Gimli ( papel , sitio web ) es un diseño de permutación criptográfica de alta velocidad con alto nivel de seguridad que se presentará en la Conferencia sobre hardware criptográfico y sistemas integrados (CHES) 2017 (25-28 de septiembre).
La tarea
Como de costumbre: para realizar la implementación utilizable de Gimli en el idioma que elija.
Debe poder tomar como entrada 384 bits (o 48 bytes, o 12 sin signo int ...) y devolver (puede modificarse en su lugar si usa punteros) el resultado de Gimli aplicado en estos 384 bits.
Se permite la conversión de entrada de decimal, hexadecimal, octal o binario.
Posibles casos de esquina
Se supone que la codificación de enteros es little-endian (por ejemplo, lo que probablemente ya tenga).
Es posible cambiar el nombre Gimlien Gpero todavía debe ser una llamada a la función.
¿Quién gana?
Este es el código de golf, por lo que gana la respuesta más corta en bytes. Se aplican reglas estándar, por supuesto.
Una implementación de referencia se proporciona a continuación.
Nota
Se ha planteado cierta preocupación:
"Hola pandilla, por favor implementa mi programa gratis en otros idiomas para que no tenga que hacerlo" (gracias a @jstnthms)
Mi respuesta es la siguiente:
Puedo hacerlo fácilmente en Java, C #, JS, Ocaml ... Es más por diversión. Actualmente, nosotros (el equipo de Gimli) lo hemos implementado (y optimizado) en AVR, Cortex-M0, Cortex-M3 / M4, Neon, SSE, SSE-Unrolled, AVX, AVX2, VHDL y Python3. :)
Sobre Gimli
El estado
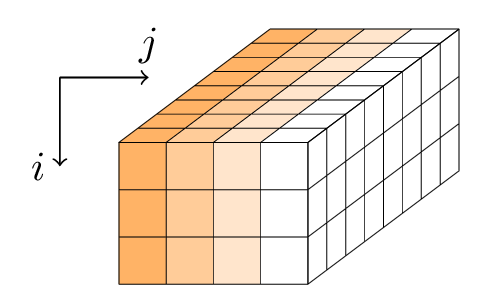
Gimli aplica una secuencia de rondas a un estado de 384 bits. El estado se representa como un paralelepípedo con dimensiones 3 × 4 × 32 o, de manera equivalente, como una matriz 3 × 4 de palabras de 32 bits.
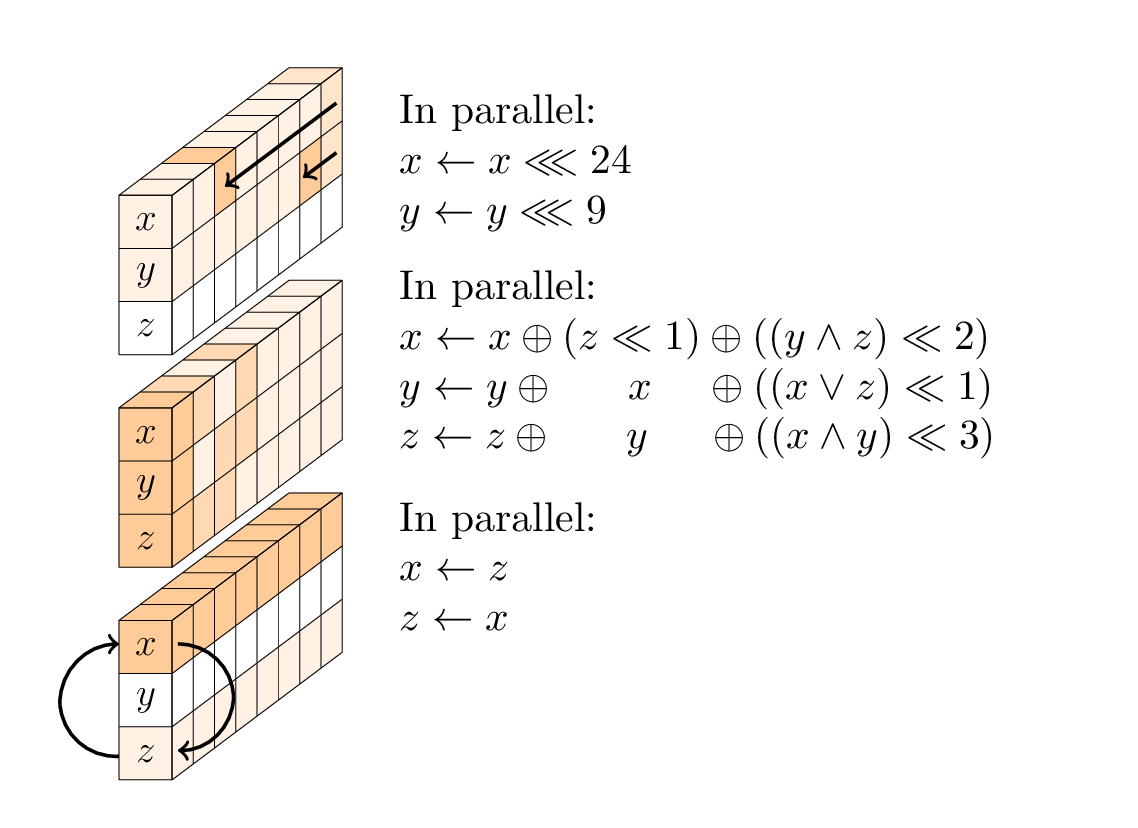
Cada ronda es una secuencia de tres operaciones:
- una capa no lineal, específicamente una caja SP de 96 bits aplicada a cada columna;
- en cada segunda ronda, una capa de mezcla lineal;
- en cada cuarta ronda, una adición constante.
La capa no lineal.
El cuadro SP consta de tres suboperaciones: rotaciones de la primera y segunda palabras; una función T no lineal de 3 entradas; y un intercambio de la primera y tercera palabras.
La capa lineal.
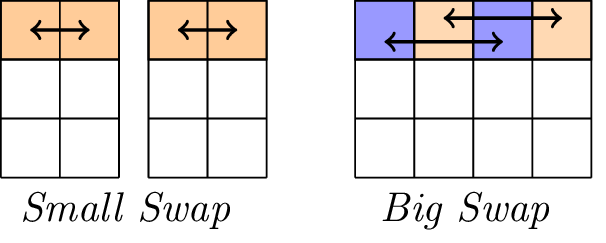
La capa lineal consta de dos operaciones de intercambio, a saber, Small-Swap y Big-Swap. Small-Swap ocurre cada 4 rondas a partir de la 1ª ronda. Big-Swap ocurre cada 4 rondas a partir de la 3ª ronda.
Las constantes redondas.
Hay 24 rondas en Gimli, numeradas 24,23, ..., 1. Cuando el número redondo r es 24,20,16,12,8,4 XOR la constante redonda (0x9e377900 XOR r) a la primera palabra de estado.
fuente de referencia en C
#include <stdint.h>
uint32_t rotate(uint32_t x, int bits)
{
if (bits == 0) return x;
return (x << bits) | (x >> (32 - bits));
}
extern void gimli(uint32_t *state)
{
int round;
int column;
uint32_t x;
uint32_t y;
uint32_t z;
for (round = 24; round > 0; --round)
{
for (column = 0; column < 4; ++column)
{
x = rotate(state[ column], 24);
y = rotate(state[4 + column], 9);
z = state[8 + column];
state[8 + column] = x ^ (z << 1) ^ ((y&z) << 2);
state[4 + column] = y ^ x ^ ((x|z) << 1);
state[column] = z ^ y ^ ((x&y) << 3);
}
if ((round & 3) == 0) { // small swap: pattern s...s...s... etc.
x = state[0];
state[0] = state[1];
state[1] = x;
x = state[2];
state[2] = state[3];
state[3] = x;
}
if ((round & 3) == 2) { // big swap: pattern ..S...S...S. etc.
x = state[0];
state[0] = state[2];
state[2] = x;
x = state[1];
state[1] = state[3];
state[3] = x;
}
if ((round & 3) == 0) { // add constant: pattern c...c...c... etc.
state[0] ^= (0x9e377900 | round);
}
}
}Versión tweetable en C
Puede que esta no sea la implementación utilizable más pequeña, pero queríamos tener una versión estándar de C (por lo tanto, sin UB y "utilizable" en una biblioteca).
#include<stdint.h>
#define P(V,W)x=V,V=W,W=x
void gimli(uint32_t*S){for(long r=24,c,x,y,z;r;--r%2?P(*S,S[1+y/2]),P(S[3],S[2-y/2]):0,*S^=y?0:0x9e377901+r)for(c=4;c--;y=r%4)x=S[c]<<24|S[c]>>8,y=S[c+4]<<9|S[c+4]>>23,z=S[c+8],S[c]=z^y^8*(x&y),S[c+4]=y^x^2*(x|z),S[c+8]=x^2*z^4*(y&z);}Vector de prueba
La siguiente entrada generada por
for (i = 0;i < 12;++i) x[i] = i * i * i + i * 0x9e3779b9;y valores "impresos" por
for (i = 0;i < 12;++i) {
printf("%08x ",x[i])
if (i % 4 == 3) printf("\n");
}así:
00000000 9e3779ba 3c6ef37a daa66d46
78dde724 1715611a b54cdb2e 53845566
f1bbcfc8 8ff34a5a 2e2ac522 cc624026
debería volver:
ba11c85a 91bad119 380ce880 d24c2c68
3eceffea 277a921c 4f73a0bd da5a9cd8
84b673f0 34e52ff7 9e2bef49 f41bb8d6
-roundlugar de--roundsignifica que nunca termina. La conversión--a un guión probablemente no se sugiere en el código :)Respuestas:
CJam (114 caracteres)
Este es un bloque anónimo (función): si desea nombrarlo,
Ganexe:G. En CJam, los nombres asignados solo pueden ser letras mayúsculas individuales. Hay espacio para agregar un comentarioe# Gimli in CJamy dejar caracteres en un solo tweet.Prueba en línea
Disección
fuente
C (gcc), 237 bytes
Probablemente gané bytes con mi método de intercambio, pero es demasiado lindo para no usarlo.
fuente
unsignedlugar deuint32_t(y el código de OP era algo engañoso usarlong) porque la idea detrás del cifrado es que es altamente portátil. (De hecho, fundamentalmente esto ahorra solo 8 bytes).gccuna CPU Intel de 32 o 64 bits (y probablemente muchos más).C, 268 caracteres (268 bytes) usando uint32_t
Nota: dado que el código original usa
<stdint.h>y escribeScomouint32_t *, creo que el uso delonges un truco para entrar en 280 caracteres a costa de la portabilidad, que es la razón para usaruint32_ten primer lugar. Si, para ser justos en la comparación, requerimos el uso consistenteuint32_ty la firma explícitavoid gimli(uint32_t *), el código original es realmente 284 caracteres, y el código de orlp es 276 caracteres.Esto se puede dividir en dos tweets con marcadores de continuación como
y
fuente
longen mi versión es seguro (con respecto a la portabilidad) porque el tamaño mínimo de un largo es de 32 bits según el estándar (en oposición aint). Las rotaciones dexyyse realizan antes del lanzamiento enlongla asignación, lo que las hace seguras (ya que el desplazamiento a la derecha del valor firmado depende de CC). El elenco al volver auint32_t* S) elimina los bits superiores y nos pone en el estado correcto :).Java (OpenJDK 8) ,
351343339320318247 + 56 bytesSolo un puerto cercano a 1: 1 de referencia para comenzar a jugar golf
Pruébalo en línea!
fuente
Integeren absoluto? o_O Dado que no usa ningúnIntegermétodo, no hay razón para no usarints aquí ...s[0]^=(0x9e377900|r);(al final): ¿no puedes dejar los paréntesis adicionales?s[4+c]>>>(23).void P(int[]S,int a,int b){int x=S[a];S[a]=S[b];S[b]=x;}void gimli(int[]S){for(int r=24,c,x,y,z;r>0;S[0]^=y<1?0x9e377901+r:0){for(c=4;c-->0;){x=S[c]<<24|S[c]>>>8;y=S[c+4]<<9|S[c+4]>>>23;z=S[c+8];S[c]=z^y^8*(x&y);S[c+4]=y^x^2*(x|z);S[c+8]=x^2*z^4*(y&z);}y=r%4;if(--r%2>0){P(S,0,1+y/2);P(S,3,2-y/2);}}}. Básicamente he realizado los cambios mínimos necesarios para que se compile. Las reglas de precedencia de Java no son muy diferentes a las de C.JavaScript (ES6), 231 bytes
Manifestación
Mostrar fragmento de código
fuente
Ensamblador x86 de 32 bits (112 bytes)
(__cdecl convención de llamadas)
Versión tweetable (codificación Base85 en formato z85):
v7vb1h> C} HbQuA91y51A: oWYw48G)? I = H /] rGf9Na> sA.DWu06 {6f # TEC ^ CM: # IeA-cstx7:>! VfVf # u * YB & mP (tuCl * + 7eENBP) $ :) Lh! k } t $ ^ wM51j% LDf $ HMAg2bB ^ MQPfuente